Blog entry by DAFFA MUSYAFA MAULANA
Menentukan Jalan Menggunakan Q-Learning
Anggota Kelompok
-Daffa Musyafa Maulana (1102194029)
-M. Athaariq Ardi (1102194209)
-Petrick Mikhael (1102174088)
Deskripsi Q-learning
Q-learning adalah algoritma pembelajaran berbasis nilai. Algoritme berbasis nilai memperbarui fungsi nilai berdasarkan persamaan (khususnya persamaan Bellman). Sedangkan tipe lainnya, policy based mengestimasi fungsi nilai dengan greedy policy yang diperoleh dari perbaikan kebijakan terakhir. Q-learning adalah pembelajar di luar kebijakan.
Deskripsi permasalahan
seorang agen harus berpindah dari titik awal ke titik akhir di sepanjang jalur yang memiliki rintangan. Agen harus mencapai target dalam jalur sesingkat mungkin tanpa mengenai rintangan dan dia harus mengikuti batas yang dicakup oleh rintangan. Demi kenyamanan kami, saya telah memperkenalkan ini dalam lingkungan grid yang disesuaikan sebagai berikut.
Tujuan
Membantu detektif sampai ke tujuan menggunakan Q-learning
Pemecahan masalah
Langkah 1: Inisialisasi Q-Table
Langkah 2: Pilih Tindakan(saat awal objek akan memilih secara acak kemana akan bergerak)
Langkah 3: Lakukan Tindakan(objek melangkah ke arah acak yang sudah dipilih sebelumnya
Langkah 4: Mengukur Imbalan(objek menilai bila mendekati tujuan +1 bila menjauhi -1 menganalisa apakah dia sudah sampai tujuan)
Langkah 5: Evaluasi(objek menganalisa apakah jalan yang dilaluinya sudah efisien
Penerapan Q-learning
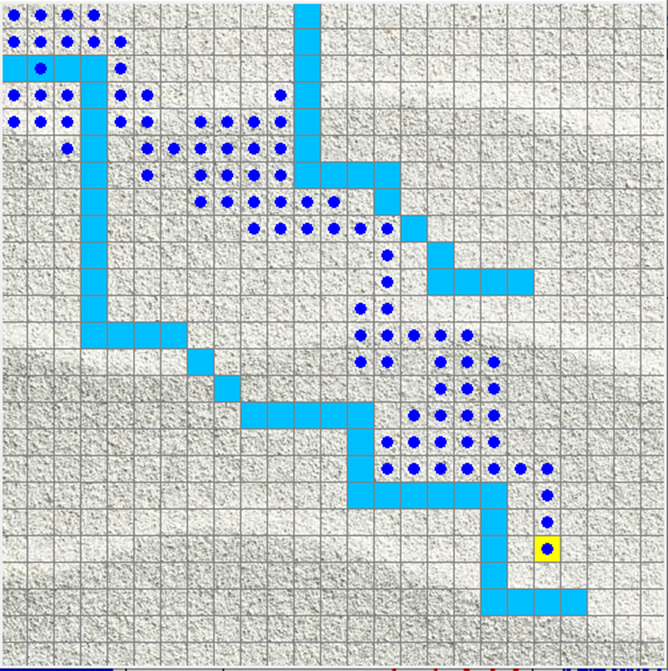
Dari gambar diatas dapat dilihat bahwa diawal objek keluar dari rintangan namun setelah itu kembali kedalam rintangan sampai ke tujuan hal itu terjadi karena Q-learning mempelajari diluar tindakan jadi setelah keluar Q-learning belajar diluar tindakan lalu berjalan menuju tujuan tanpa keluar rintangan lagi
Kesimpulan
Jadi disini kami membuat Tubes AI yang berjudul Menentukan Jalan Menggunakan Q-learning.Dengan menggunakan Q-learning menemukan jalan dapat dilakukan dengan lebih efisien karena objek tidak harus berjalan menelusuri seluruh wilayah dulu untuk mencapai tujuan namun cukup melangkah acak pada langkah pertama lalu berikutnya objek akan belajar secara mandiri tentang langkahnya selanjutnya dapat dilihat seperti gambar saat presentasi bahwa objek di awal keluar rintangan namun setelah itu kembali masuk kedalam lintasan dan tidak pernah keluar rintangan lagi sampai ke titik tujuan
Sumber:https://towardsdatascience.com/a-beginners-guide-to-q-learning-c3e2a30a653c